
So the weapon this week is one I always look very thoroughly at since I know how hard it can be to get right. Weapon, so we are looking at weak spots. How about the rhyme? Well, let us see what we have:
”Don´t take for granted a transaction will run
Uninterrupted with nothing to spoil the fun
Integrations might be broken, sessions might time out
Make sure you test those scenarious throughout”
So, what does it mean?
Oh joy!
So. Imagine a user walking from start to finish through your system.
From their perspective this should be like I imagine the yellow brick road in my mind. Bright, wide, paved. Clearly guiding them to where they want to go. Nothing to show switches in technology, services, integrations or applications. Just smooth sailing.
Underneath – that might require some serious action to achieve.

I would like us to look at transactions (with a touch of message handling)
Note: To simplify for the sake of this blog post, assume that a transaction can/will cover multiple services/applications/tech stacks. If you want to call it something else, because a transaction for you is limited to a single service/procedure/anything, please do. In this post, we will call them transactions regardless on how many potential services they cover.
Transactions, from my point of view, are basically a number of things, or actions, that should be handled as if they were the same action. They all need to be completed in order for something to be considered done. (see better description here)
If we are completing an online order, it would not do to have half of the information about the order generated in system A but not the other half in system B. If one fails, the other needs to be handled in some controlled way.
This cards deals with the complexity of transactions, interruptions along the way and how we as testers should challenge assumptions around them.
Over the years, I’ve heard a lot of different approaches to transactions. Depending on tech stack, type of application the problems in the particular business or other aspects, you can approach them in a lot of ways.
Do you keep them tiny or do you try to contain more?
Do you have transactions within transactions?
How do you handle sets or chains of transactions, internally and/or in-between applications?
What should you do when a transaction fails? (Try again, roll-back, error list, other?)
From one perspective, we want to keep transactions tiny. Quick, tight and resource-friendly.
On the other hand, we want to maintain data integrity and allow for a good way of handling errors along the way.
In the stone ages, when I programmed for a living, transaction scope was a pain! Both due to resource optimization but also because the balancing act was very delicate.
Nowadays it seems developers don’t pay as much attention to it, expecting the framework or IDE to handle it.
With the shift from monoliths to small services, the complexity also increases, due to the fact that there are so many integration points and you might only be able to control one tiny part of the big scope.
So, having conversations with developers about the full chain of transaction as well as about how transactions within a certain service/system is handled, is a great way of finding holes and weak points.
”What will happen if X is down?” is one of my favourite questions.
Have someone walk you through a chain and discuss each point of integration and/or transaction scope and you will learn so much useful information about your system, your teammates, the tech stack etc.
Including someone from the business side for the walkthrough is even better! They might not expect the behaviour to be the same as how the developer imagines it.
The complexity of synchronous/asynchronous messaging, illustrated by the two generals’ problem, is another topic worth some deeper reading.
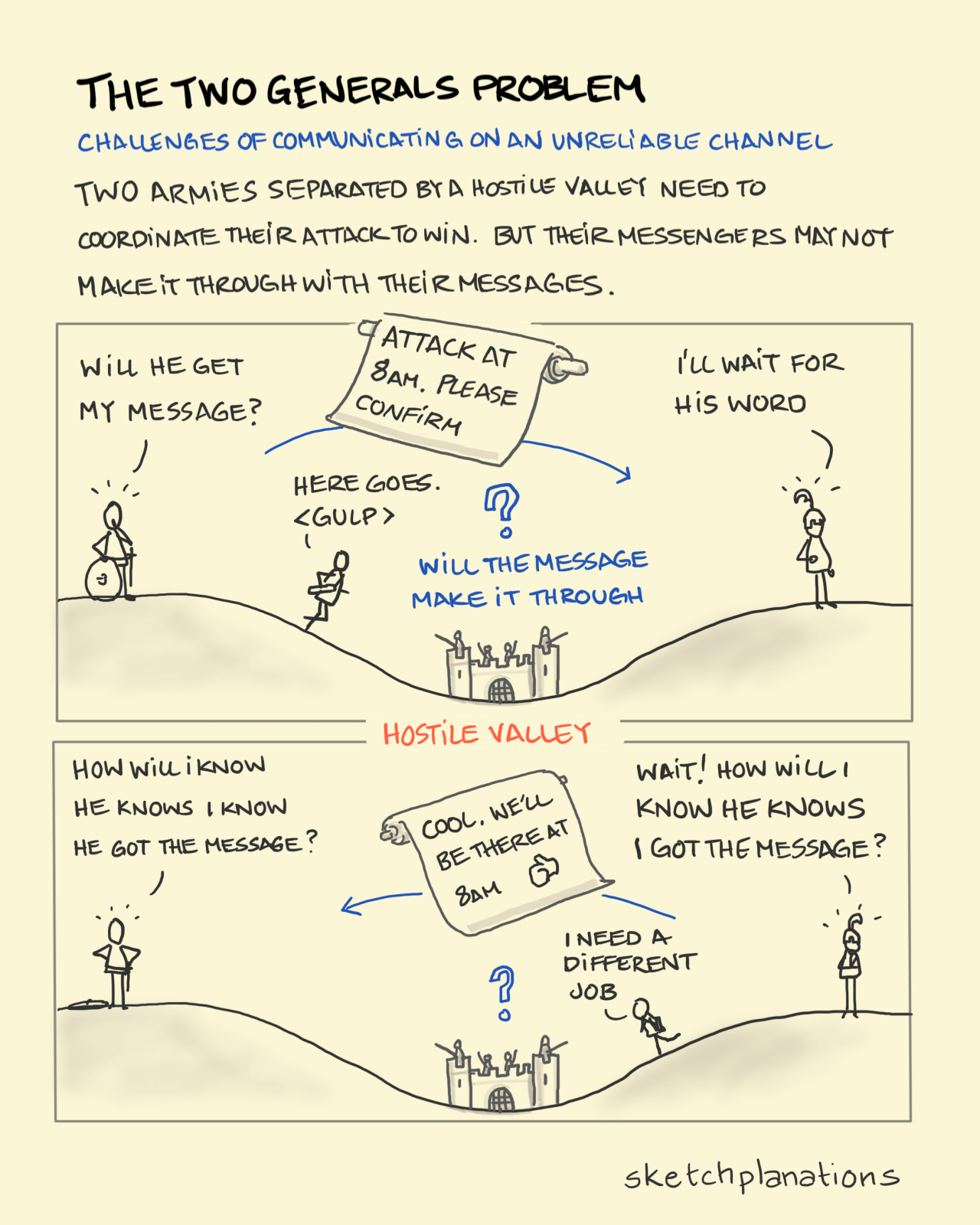
Story time
So, at one point in time we were fixing a large issue by rewriting a certain feature in the system.
From start to end that feature would rely on a lot of things.
To make it a bit more anonymous, let us imagine that this feature was that a user could apply for a job with us, including a resume attached as a file.
The service would use the personal number to get address from an external source, outside of the company. The file would be uploaded through a different external source, inside of the company but handled by another team. A third external source was also included to.. lets say add information about the Linkedin-profile.
A number of internal sources were also involved, both services handled by the team and messaging services to handle queueing.
Finally – the application would be passed on to another system.
Some of the applications were online 24/7, some only office hours.
Multiple different tech stacks involved.
So, I had one of the developers talk me through the chain of events involved when a user hit the submit button. What was created when, in what order etc. Halfway through I found a point where my experience said we could end up in a situation where our own application had posts generated while one or more of the integrating systems had still not verified that they had accepted the request. A simple ”what will happen if system B is down?” started a discussion ending in us re-structuring the order of calls and events to make it more robust.
Quote of the day
”…how can there be a rational, effective design if no one on the design team can walk you through the more important transactions, step by step and alternative by alternative. I’m sure that mine is a biased sample, but every system I’ve ever seen that was in serious trouble had no transaction flows documented, nor had the designers provided anything that approximated that kind of functional representation; however, it’s certainly possible to have a bad design even with transaction flows. ”
Boris Beizer – Software Testing Techniques 2E
Reading suggestions
Transaction processing – Wikipedia
ACID transactions – Wikipedia
Two Generals’ Problem – Wikipedia
Transaction flow testing – Sakshi education
Brave new geek blog – tag two generals’ problem – Brave new geek
Software Test Engineer’s Handbook – Graham Bath, Judy McKay
Previous posts in the series
| Title and link | Category |
| Part 1: Introduction | None |
| Part 2: Mischievous Misconceptions | Trap |
| Part 3: The Rift | Weapon |
| Part 4: The Fascade | Tool |
| Part 5: The Temptress’ Trails | Trap |
| Part 6: Allies | Weapon |
| Part 7: Don’t turn back | Tool |
| Part 8: The Glutton | Trap |
| Part 9: Beyond the border | Weapon |
| Part 10: Forever and never | Tool |
| Part 11: The Shallows | Trap |
| Part 12: The Twins | Weapon |
| Part 13: The Observer | Tool |
| Part 14: Alethephobia | Trap |