
Note: This was originally published as a guest blog post for DevTestOps Community.
I started a new job a few years back, with one of my responsibilities stated as “Move the existing automation to the next level”. The company already had a lot of automated tests in place and had worked really hard on making automation a part of the normal team delivery. Great! I´ve worked with a lot of problematic automation and I know a thing or two about what not to do. So, it sounded like a dream!
In my vision, I saw a pipeline where all tests run green and if it fails, we fix it ASAP and it is green the next morning. In reality however, most days at least something had failed. To me, it felt like no one was very worried about it. I worried. And I had a hunch there was a pattern, but I couldn’t pinpoint it when looking at each individual test run. So, I pulled all the historic data, put it into a spreadsheet and started twisting and turning it to look at it from different perspectives. At the same time, I started asking a lot of questions to people from the teams furthest along the automation route who were involved and/or affected by the automation in different ways. Those included testers, scrum masters, developers, architects, product owners, operations and management.
The questions depended on the roles but revolved around finding out how much confidence people had in the automation, how much time they spent on maintaining them vs. improving them and how I could help move things forward.
I had a few questions and hypotheses I wanted to answer, such as:
• Were we addressing the actual problem or did we just re-run them locally and blame the environment?
• Were they run as often as we needed them, or could they be sped up to a point where they could provide more value to the teams?
• Were there problems that could be solved, with the right people and/or resources available?
• What problems were we actually trying to solve with these suites?
A few things quickly stood out, clear as day.
• People were so caught up in the daily deliveries that they didn´t feel they had time to work pro-actively on continuous improvements.
• People felt a lot of the issues were “impossible to fix”, because they lacked the right competence in the team
• We were trying to solve a multitude of problems with the same set of tests.
• A number of tests had never succeeded. And a number had never failed.
Ok, with the problems defined we can finally try to figure out a solution! Let us dive into each one and see what can be done.
Breaking out of the hamster wheel
Problem: People were so caught up in the daily deliveries that they didn´t feel they had time to work pro-actively on continuous improvements.
One issue with most software development out there is that unless specifically making room for it, refactoring is always a struggle. To me, it has always been a part of continuous improvement and I usually have no problem creating a business case for it. I do, however, see that a lot of people out there, testers as well as developers, aren´t trained to sell that story. And as a result, they often (feel like they) get too little time to do more than deliver the stories that are in the current pile of “to do now”.
But never looking at the bigger picture means building tech debt, which in turn means increased maintenance cost and less and less value delivered. What I saw here was a never-ending cycle of
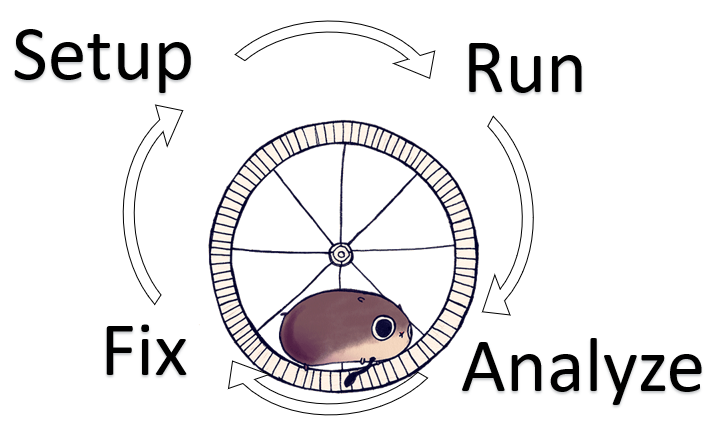
• Analyse the last run (never trends, always the last run)
• Debug found issues
• Fix said issued
• Setup for nightly run
• Repeat
This meant that we never took time to work on improving (proactive) only fixing (reactive). And adding more of course. And as a result, completing the cycle took longer and longer, which reduced the available time for improvement. And while you are in this loop – it is really hard to see it!
In this case I had a role and background where I could help but if you don´t – find a sponsor! A sponsor could be someone who can help you prepare the business case, someone with access to a budget who can finance it or why not someone with the organizational power to prioritize your ideas. Depending on where you work this could be different people, but a product owner, a manager or a team lead could be starting points.
The power of relationships is a topic for a separate blog post (I talk about it in “My journey from developer to tester” and Alex Schladebeck & Huib Schoots talk about it in their “Jedi mind tricks for testers”) but trust me on this:
People want to help people they like and we like people who like us.
So save yourself a lot of trouble and work on those relationships!
Making the impossible possible
Problem: People felt a lot of the issues were “impossible to fix”, because they lacked the right competence in the team
So ok, talking to people about the failing tests, people kept saying the issues where “impossible to fix”. Therefore, the tests were just re-run locally and if they passed nothing more was done to them. Which could of course be ok, there are tests that just randomly fail at times for no apparent reason, but when looking a bit deeper I could find a number of actual problems related to certain areas.
Operations and hardware
In this group goes all the problems that I could trace back to things that the teams felt were out of their control and that are also related to the operations department. Things like:
“Oh, our firewall does not allow us to do X, so we needed to do Y to get around it”
“The tests fail if they start late or take longer than usual because at 3am they backup system A”
“Yes, they crash every 3rd Monday of the month but that´s only because we do patches then”
Issues in this category could be time related such as backups, patches, batch jobs or applications closed certain hours and network related such as firewalls, DNSs, blocked/trusted sites or queues filling up.
Or course, if you don´t have any experience with operations these things might look unavoidable but most of the time they can be sorted by explaining your problem to someone with experience and ask for help.
Potential solutions can range from rescheduling tests, separation of domains, re-configuration of hardware or even by throwing money at it! Explain to someone with the power to change things why this would save money/time and/or increase team/customer satisfaction.
Test environments and test data
Here go problems related to the bane of many a tester: environments, integrations and data. Comments I sort into this group were:
“The test failed because the data was used up by another test”
“The test run last night failed because someone was locking the environment”
“That´s not a bug, it only failed because Service X was down/had the wrong data”
Potential problems here could be concurrency, corrupted data, race conditions, data limitations, limited capacity of the environments, limited number of environments, (unnecessary) dependencies to services that were down and/or had the wrong data/version/state/configuration.
These are, of course, not easily fixed. However, a lot can be improved by some pretty standard practices today such as using synthesized data when possible, removing dependencies with mocks/stubs when possible, using virtual environments that can be spun up when needed, cleaning up data after a run, tests creating their own data instead of looking for existing, asking for more/better environment, getting help from management and/or operations to get the resources and prerequisites needed for a good, modern setup of environments and data. (Throwing money at it can go a long way to ease the pain!)
Processes and communication
Oh, my this is a big one…. In this big pile of opportunities for improvement you could find gold nuggets such as:
“We didn’t know the code has changed so we didn´t know the tests needed to be updated!”
“We didn’t have time to fix the tests because we were busy implementing new tests!”
“Oh, yes that happened because the application in that environment was version X, we can only test version X.Y”
Potential problems related to this group are of course either communication and/or process related. It could be that code changes are not communicated within the team or between teams with dependencies. It could be that those changes were communicated but that no one prioritized fixing it.
It could be that no one had seen the benefits of being able to run multiple versions of a test suite, say to be able to quickly test both planned releases and urgent patches.
Or it could be that we were trying to solve multiple problems with the same set of tests, which I will get back to under “One size fit no one” below.
Or of course a lot of other things that could be their own series of posts so let’s stick to the ones mentioned above.
These are both really hard and really easy to fix, depending on the individuals, teams and/or organization. A lot should be obvious (but is apparently not always implemented in reality), such as making sure testers (whichever formal role they might have) are included from start to end. Good things to try to improve this are 3 Amigos sessions, Pair-programming, mobbingor just making sure test is always included in discussions about both problem and solution.
Communication breaking down between roles and/or teams is a strong anti-pattern and when you see this it should be on everyone´s priority to work on that problem. Ask for help if it seems too big to handle yourselves. Asking the other teams what information they would be helped by and how they would prefer to get it will improve both relationships and understanding of each other´s problems, needs and domain. And relationships matter, a lot!
Running tests that we know will fail (say we didn´t have time to update them all) is a waste of time and resources and will create noise. A simple solution for that is to disable them until you know they should pass again and put some more effort into testing those areas in other ways. (Or take an informed decision to accept the risk for now)
Not version-handling tests is a problem I was extremely flabbergasted by. Version handling other types of code has been a standard for years, but I keep hearing about tests not following the same pattern. We should of course be able to run the exact version or a test and/or test suite that we need at that point, in that particular environment. This should be standard procedure and since most companies use some kind of version control system today, it should be very, very low effort to implement it. I see no reason not to do this already, it should not be a limitation anywhere today. And if you don´t already – put your test automation code with your production code whenever possible! They should not be separated; they are part of a whole.
One size fit no one: Use the right tool for the job
Problem: We were trying to solve a multitude of problems with the same set of tests.
Another of the anti-patterns I saw was that the test automation suite was used as a band-aid to fulfil a number of different needs for information, on different levels. Sometimes these were even in direct conflict with each other.
We had the developers, who wanted ultrafast feedback on changes. Having that would allow them to make changes without worrying that their changes broke something else. For them, a red test might be expected or even wanted, applying a test-first perspective on the development. As long as they were fixed fast of course, otherwise the red tests are just noise.
Then we had testers, who wanted quick feedback on the stability of a certain release candidate as well as the security of knowing that the existing regression tests were still ok. Having that would allow them to focus their testing on changes and/or exploring certain aspects of the software instead of having to waste time on something unstable, finding obvious bugs or testing all of the old functionality again. They also needed to be able to test different release candidates at the same time and possibly with different sets of data. To them, a failing test should mean a problem had been found, meaning something needs to be fixed ASAP. It should not mean wasting time on analysing the result or missing actual problems because the report was full of noise.
The product owner and the scrum master wanted the tests to answer questions related to planning and stability, such as “Is this release candidate ready for release?”. To them, a failing test should mean either not releasing or taking a quick decision that the problem was not bad enough to stop the release.
And then we had people like me, managers, who wanted information about strategic planning and investments, such as “Are we spending our money in the right places?”. And to do that, I wanted to look at trends, improvements, root cause analyses and things like that.
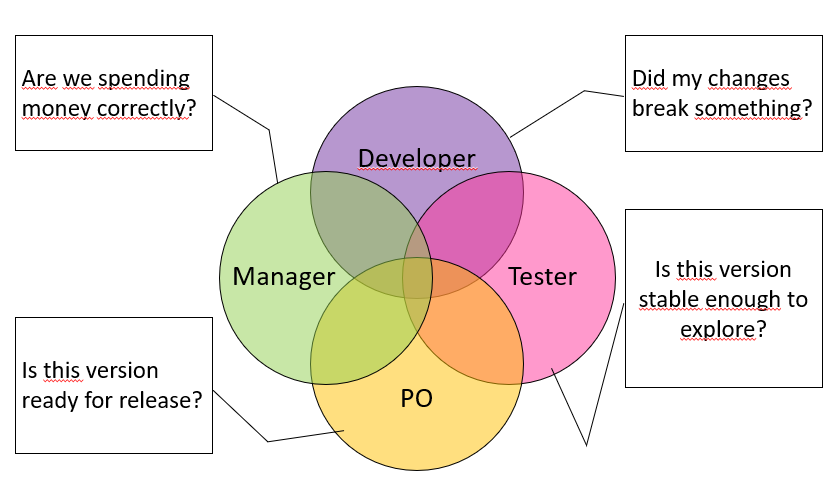
Of course, all of these questions and needs can´t be met by running a single suite of automated tests in a single environment, with a single set of test data.
The solution to this might require a separate blog post but using layers of tests for different purposes and using different versions, data sets and environments is the short answer.
Dare to delete. It´s ok, I promise.
Problem: A number of tests had never succeeded. And a number had never failed.
One thing I found that I thought would be simple to fix turned out to be very hard to convince people about. Deleting tests.
To me, a test should only be run if it has a value greater than the cost, but I realized that the emotional barrier to removing something that you had invested in was a lot greater than I anticipated. Of course, there is no easy answer to when they start costing to much, since that depends on your context, but measuring total run time and total time for maintenance over time is a good idea. Monitor if any of those metrics start rising without a good reason and try to set at least yearly goals for improvements.
I suggested a few things that I wanted to do:
- Remove the tests that had never, once, failed.
To me, they were noise that simply made us feel good about having a higher % or passes and at the same time increasing the complexity of the test suite and the cost for running them (time and resources). People did really not want to do this because they felt it would lower the test coverage, but I argue that unless they test something relevant; they are not providing value. And to me, a test that never failed is by nature a bit suspicious.
They might, of course, be important! But I would at least make sure they are not always successful because they are asserting the wrong things.
It might also be that we never, in several years, changed anything in that area. In that case, do we need to run them every night? Removing does not mean you can never ever get them back but maybe there are other things more important to use those resources for right now? - Remove the test that had never, once, passed.
Honestly, if you haven´t fixed the test in a year, why bother running it? Here, the argument was that we would lose coverage and that they were needed but this is frankly a hill I am prepared to die on. Fix or delete, there is no “what if”-here. Do it.
So, to sum this all up…
In the words of Ian Fleming: “Once is happenstance. Twice is coincidence. Three times is enemy action”. Looking at trends rather than only at the current state will help you see patterns that can help you find areas where changes will have big impacts.
Asking for help and/or input is a great way of improving. Involving people with other areas of expertise might solve problems you though were unsurpassable. I know for a fact that my perspective fixed a few, and I have had other people solve my unsolvable problems more than once. Impossible might be possible with another set of tools.
As a professional working with tests, it is your job to make room for continuous improvements. No one can create time, but everyone can raise the issue. And honestly, making time for this type of work will save time in the end. And if you are a manager, it is your job to help people see when they are getting caught up in the daily business and help make room.
And in the words of Marie Kondo: “Do these tests spark joy?”
Kon Mari your tests on a regular basis!