
The Pattern beyond the pixels – You get what you measure
In the previous parts we covered the project and the problem, reactive work and the stress cone, and the possibility to change what looks unchangeable. Now we are getting into something that I believe is a killer of a lot of change initiatives, and many first steps into automation: measuring the wrong things, and not noticing you’re doing it.

The number everyone was watching
When I arrived and started looking at the data, there was one thing in particular that we were measuring: Number of automated tests. And that was going up. More tests, sprint after sprint. And when you are starting out on an automation journey – that is a logical metric to track — more tests is generally good. Just like code coverage. (Both of which, I should add, I have seen gamed spectacularly) If you are measuring nothing – code coverage is a place to start. Unfortunately, it is not very valuable in the long run, and it doesn’t tell you much about the actual quality. But it had become the metric. The number that appeared in demos, got referenced in status updates and was used as evidence that things were heading in the right direction.
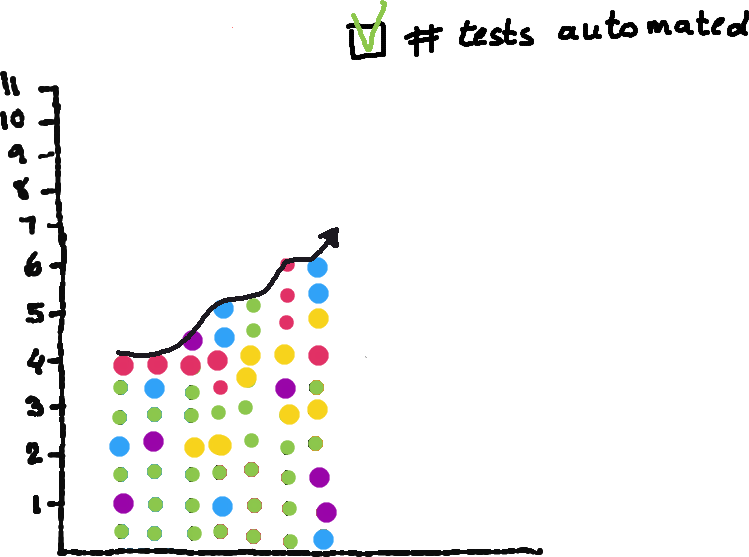
That was it. We were measuring what was easy to measure. What nobody was measuring was whether those tests were actually providing value.
How well were they doing? Were they finding bugs? Were they providing more value than they cost? What were the execution times? How much time was being spent on maintenance? Noone was asking anything about that, about actual value. And what you don’t ask, you don’t answer. What you don’t answer, you don’t act on. And, gradually, we started optimising for that metric. (Which is exactly what you’d expect. Metrics are a bit like wishes so be careful what you ask for.)
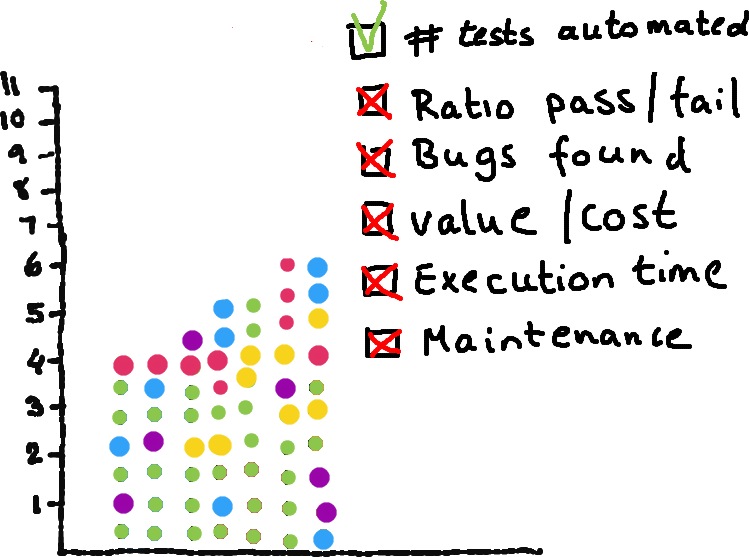
You need to think actively about what is valuable to you — and whether what you’re measuring actually reflects that. Because measuring bleeds into behaviour in interesting ways. If you tie people’s personal goals (which are ultimately, unfortunately, tied to their performance reviews, financial compensation, promotions and opportunities) to how much automation work they do, they may deprioritise other work that would actually be more valuable right now. If team metrics are heavily focused on delivery, or you push people too much into team focus, individuals might stop considering whether helping another team is a better use of their time that week. Metrics shape behaviour, and you can’t optimise for everything, so you need to really think about which behaviours you’re shaping.
What is it actually saying?
A pass or fail only tells part of the story. It might not even be telling the interesting part — and your interpretation might be completely wrong. If you only look above ground, you can’t see the true value of the carrot.

If tests are failing: why are they failing? Why are they never fixed? Are there obstacles nobody is seeing? Unstable areas? Complicated business logic? Tests that are simply too long with too many steps that can go wrong?
In my story, we had tests that had never once passed. We kept running them. We didn’t fix them. Sometimes they found problems. All of the time they added noise. I still to this day do not understand the reasoning behind keeping them but I strongly suspect it was tied to the metric ”number of automated tests” rather than any sense of value.
And just as interesting, if tests are always passing: what are they actually doing? Can you trust them? Do they add value, or are we only keeping them to keep the numbers looking good? We also had tests that had never failed. In five years time. We kept running them. But more alarmingly, we didn’t question it. And some readers might raise an eyebrow here. (Hi! Lovely having disagreeing minds here!) Does this sound familiar? Why would you question a green test? Well, for starters, they are a cost. And they make me suspicious,because normally tests fail sometimes. There are of couse valid reasons. Maybe that is an incredibly stable area of the system. Maybe the complexity of the code, and the test, is very low. Maybe it is an area we are extra careful changing. Or, in my experience more likely*, they are not doing what they are supposed to be doing.
Noise
All of this is (can be) noise. So much noise had built up and become normalised.
If a test fails once, people look at it. If it fails twice, they start to wonder. If it fails every third Monday because of patch day, or every time a particular environment is busy, they stop looking. It becomes background noise. Known. Accepted. And by that point, quietly devastating to the usefulness of the whole suite.

Every false alarm costs someone time and attention. Open the report, see a failure, spend mental energy deciding: is this a real problem or just the usual? Do that enough times and people stop engaging properly. They start pattern-matching on ”probably fine” instead of genuinely investigating. Which means that when an actual problem appears, it can hide in the noise far longer than it should.
And the same report can mean completely different things depending on how much noise is in it. A 65% pass rate where most failures are known infrastructure issues is a very different situation from a 65% pass rate where every red test is a genuine problem. The number looks identical. The reality is not.
You absolutely need to get rid of the noise. Fix the root problems when you can. Work on testability. Hey, buy a new tool of it helps. But there also has to be a cultural shift: stop tolerating known, recurring noise and calling it ”just how things are.” Every unaddressed source of false failures is debt. And like all debt, it is mostly unwanted.
What should you actually measure?
There’s no single right answer, and context matters a lot. As I previously said, when starting out it might be valuable to know the number of automated cases increase. After a while, other things are needed.
Start from the questions you actually need answered, not from what’s easiest to report.
The question to start from is: what is actually valuable to us right now? Fast time to fix when something breaks? A reliable pass/fail signal before a release? Low maintenance cost over time? Understanding development velocity? All of these are legitimate, but they lead to very different things to measure — and very different interpretations of the same data.
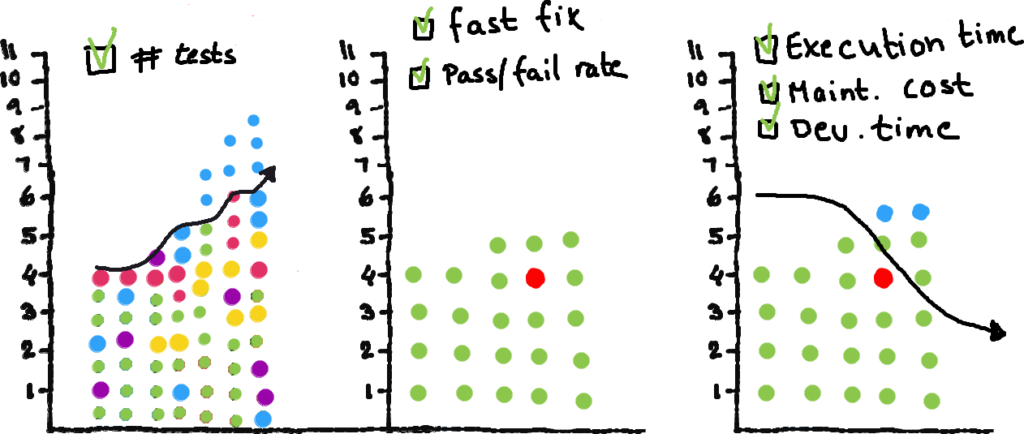
Metrics should serve those questions. That means actively choosing what to measure — not just counting what’s convenient to count.
Is the cost of our automation worth it? How much is it costing us to build and maintain? Is our infrastructure cost going up? How long do they require to run? How much time does it take to fix a test? Is it helping us moving to market faster? Set some guard rail, monitor shifts and set (at least) yearly goal. And constantly ask yourself if your current metrics are serving you still.
In part five we’ll dig into something closely related: the danger of trying to answer all of our questions with the same set of tests, but also – getting into my last epiphany (so far) from this project. It was never about automation. .
* Disclaimer: Unless we are talking about low level tests that are fixed by developers before I even see them, but those are not the types of tests in my story. Also, they should also fail. And be fixed.